Agent failures often look like model failures, but many of them are runtime failures.
A modern agent system is not just a model call. It is a moving bundle of prompts, provider settings, tool schemas, file operations, sandbox state, retries, partial outputs, and validation checks. When the bundle is small, a transcript may be enough. When the bundle grows, a transcript is too thin: it tells you what was said, but not enough about what was executed. This is the same pressure that made tool-use agents, traceable runs, and durable workflow state become central topics in current agent infrastructure.[1][2][3]
This is why agent debugging can feel strangely opaque. The model may produce a reasonable final answer while the tool wrote to the wrong directory. A provider may reject a model name that looked valid in another environment. A workflow may fork into two promising branches, but the final output may hide which branch actually introduced a useful edit. These are not philosophical problems. They are ordinary engineering problems caused by missing runtime evidence.
The common workaround is to collect more logs. Logs help, but they are usually outside the object that users manipulate. They are easy to lose, hard to merge, and hard to compare across runs. A durable runtime needs a stronger unit: an object that can carry the conversation, the tool effects, the environment identity, and the ancestry of the work.
This is a familiar pattern outside of agents. Databases do not treat a commit as a friendly string printed to stdout; they write records. Distributed systems do not debug incidents only from the last response body; they need traces, spans, and causality. Build systems do not trust a final message that says "done"; they care about inputs, outputs, caches, and invalidation. Agent runtimes are reaching the same stage. The model is important, but the model is no longer the whole system.[4]
There are three recurring traps. The first is provider drift: the same code path works against one OpenAI-compatible gateway and fails against another because model names, streaming chunks, tool-call deltas, or usage fields differ. The second is environment drift: the agent writes a file, installs a package, or runs a command in an environment that the reviewer cannot reconstruct later. The third is workflow drift: an agent tries several branches, but the final answer erases which branch produced the decisive evidence. Each trap looks small in isolation. Together they make long-running agent work difficult to trust. Real-world coding-agent benchmarks have made this visible by evaluating agents against repository issues rather than isolated toy tasks.[5]
This is why a runtime boundary matters. A prompt can ask the model to be careful. A logger can record more text. But neither one defines what the user should treat as the durable unit of work. If the unit is only the final answer, debugging becomes forensic reconstruction. If the unit is a session with structured evidence, debugging becomes reading a record.
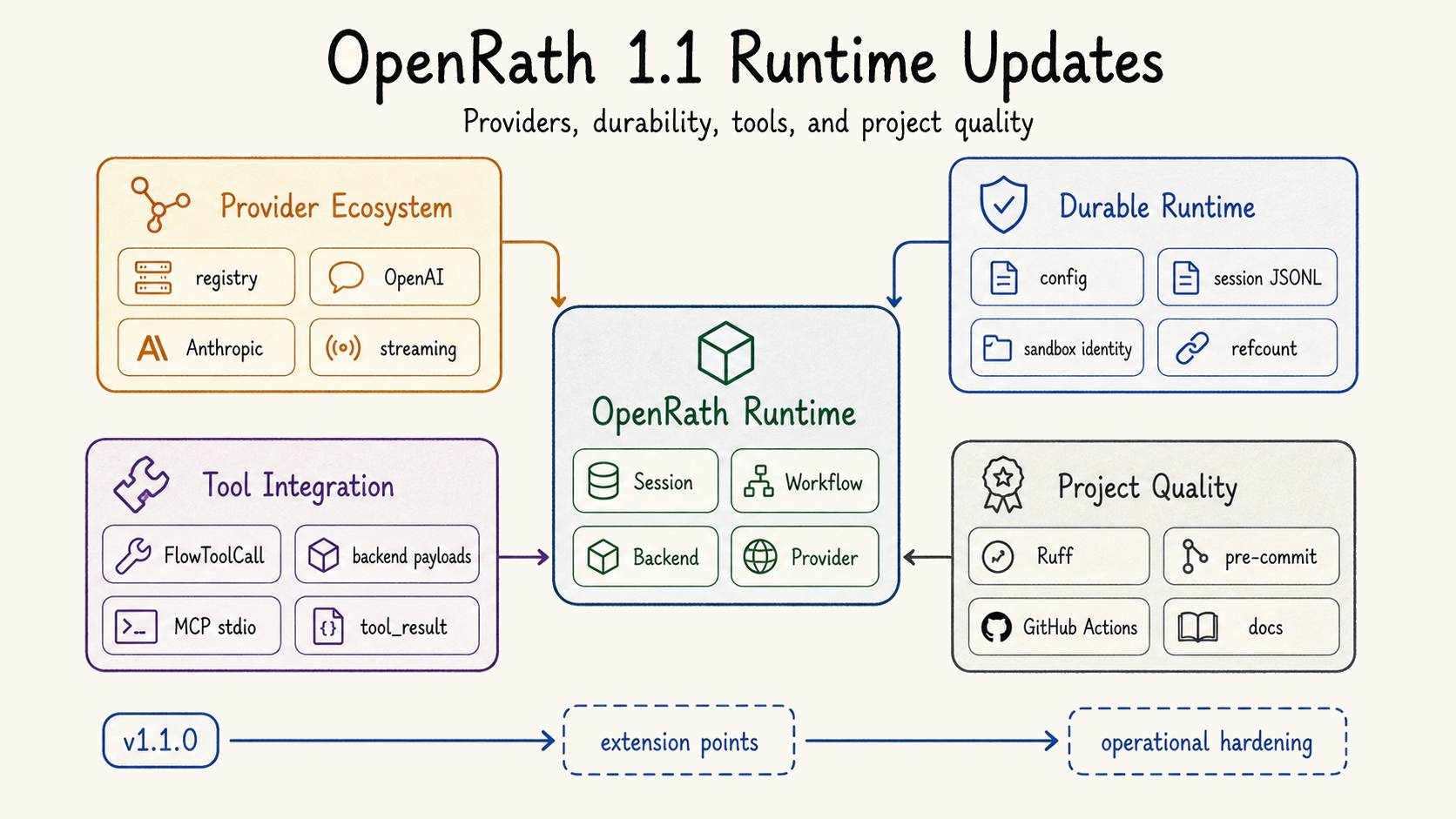
The field is converging on runtime structure, even when it uses different names.
The most useful recent work around agents is not only about stronger models. It is also about the machinery around the model: tool contracts, traces, checkpoints, persistent state, and evaluations that happen inside real repositories.
The first trend is tool use becoming a runtime concern. ReAct framed language models as systems that interleave reasoning and actions, while Toolformer showed that tool use can be learned as part of a model's behavior.[1][8] More recent protocol work such as MCP turns tools into named server-side capabilities with schemas and transports, rather than one-off Python functions hidden inside an application.[6]
The second trend is observability. OpenAI's Agents SDK exposes tracing as an explicit surface, and distributed-systems practice has long treated traces and spans as the way to recover causal paths through a system.[2][4] For agents, the analogous question is not just which HTTP services were called; it is which model event, tool call, file edit, and validation step caused the final answer.
The third trend is durability. LangGraph documents durable execution around checkpoints; Temporal's workflow model treats execution history as the basis for durable, replayable workflows; LlamaIndex and AutoGen expose workflow or agent state as something that can be saved and resumed.[3][9][10][11] OpenRath's design is smaller in scope, but it follows the same pressure: long-running agent work needs durable state boundaries.
The fourth trend is evaluation moving closer to production. SWE-bench evaluates whether language models can resolve real GitHub issues, which makes repository state, tests, and patches central to the task.[5] That direction makes transcript-only evidence less satisfying. When the unit of work is a repository change, the runtime should preserve the path from failure signal to patch to validation.
| External pressure | What it teaches | OpenRath response |
|---|---|---|
| Tool-use agents | Actions need schemas, results, and a place in the execution record. | FlowToolCall, backend tool payloads, MCP adapters, and tool-result chunks. |
| Tracing | Final outputs are not enough; causal paths need to be recoverable. | Session chunks, stream deltas, lineage export, and persisted JSONL rows. |
| Durable workflows | Long-running work needs checkpoints and resumable state. | Session persistence, sandbox identity, lazy sandbox reopen, and refcounted handles. |
| Real-repo evaluation | The environment and validation gates are part of the task. | Sandbox-bound tools, CI-oriented docs examples, and validation-aware session records. |
A concrete failure: the code was fine, but the runtime contract had drifted.
During the work that led to this release, we used a real OpenRath example as a small production-like test. The example compiled. The documentation looked plausible. The provider helper loaded a DeepSeek-compatible endpoint from the environment. Then the run failed because the example overrode that configuration with a hard-coded model name from another provider family.
provider = replace(provider_from_env(), model="glm-5.1")The provider response was ordinary and useful: this endpoint supported `deepseek-v4-pro` or `deepseek-v4-flash`, not `glm-5.1`. The right repair was not a clever prompt. It was to remove the provider-specific override and let the runtime configuration decide the model.
provider = provider_from_env()This is a small case, but it captures a large class of failures. The model did not forget how to code. The project had drift between example code, provider configuration, tutorial text, and live execution. A final answer alone would not tell us which layer drifted. A useful runtime record needs to package the failure signal, the file edit, the lint check, and the final validation together.
The repair itself was almost boring. That is why the case is useful. Hard agent problems are not always solved by a spectacular reasoning trace. Many are solved by connecting a plain error message to the exact file and runtime context that produced it. The agent needs enough state to avoid guessing from a summary. The human reviewer needs enough state to verify that the fix did not merely silence the symptom.
| Stage | Signal | What the signal teaches |
|---|---|---|
| Static check | The example compiled. | Syntax is too shallow to detect provider/model mismatch. |
| Runtime failure | The provider rejected `glm-5.1` for the configured endpoint. | The failure belonged to the provider boundary, not the Python parser. |
| Patch | The hard-coded override was removed. | The example should respect the configured provider instead of replacing it locally. |
| Final validation | Compile, lint cleanup, and live execution passed. | The repair was grounded in checks, not just a plausible explanation. |
A capable model can read the error and propose the same patch. The runtime question is different: can the system preserve the evidence that made the patch credible? If the answer is no, every reviewer has to reconstruct the run by hand. If the answer is yes, the session becomes an audit trail for both the agent and the human.
The core problem is not memory. It is where runtime evidence lives.
"Memory" is a vague word in agent systems. It can mean conversation history, vector search, user preferences, tool output, checkpoint state, or a saved workspace. The more precise question for OpenRath is: what should be attached to the session as evidence of a run?
Our answer is that a session should carry at least five kinds of evidence. It should carry the model interaction, the tool calls and results, the environment identity where those tools ran, the lineage of branches and merges, and the validation signals that make the run trustworthy. If any of these live only in external logs, the user can no longer treat the session as the unit of work.
A useful mental model is event sourcing for agent work. The final answer is a projection. The session is the record. Tool calls, tool results, stream deltas, provider metadata, sandbox identity, and merge ancestry are not decorations around the answer; they are the evidence that lets a user understand the answer.
| Evidence type | Common weak version | Durable version |
|---|---|---|
| Conversation | A chat transcript. | Typed chunks that can be replayed, compressed, or inspected. |
| Environment | "It ran somewhere in a sandbox." | A persistent sandbox identity attached to the session. |
| Tools | Opaque function calls in a log line. | Structured tool-call chunks and tool results. |
| Branching | Manual notes about which attempt worked. | Fork, detach, merge, and lineage metadata. |
| Validation | A final success message. | Checks connected to the run that produced the change. |
The useful ideas are old: event logs, checkpoints, identity, adapters, and provenance.
OpenRath v1.1 is not trying to invent a mysterious new theory of agents. It applies familiar systems ideas to agent workflows, where they are newly urgent because model calls, tool calls, and mutable workspaces now interact in one loop.
The first idea is event logging. If a run is a sequence of typed events, then a final answer is only one projection of that sequence. Text chunks, tool-call deltas, tool results, retries, and validation checks become inspectable records. This is why streaming is more than UI polish: the same events that make a page feel alive can also become evidence after the run.
The second idea is checkpointing. A workflow that can pause, resume, or branch needs stable state. For agents, state is not only the chat transcript. It is also the sandbox where code ran, the provider configuration used for the model call, and the file tree modified by tools. Without checkpoints, the user can rerun the prompt but not necessarily rerun the same work.
The third idea is identity. A sandbox is not just an implementation detail; it is part of the execution environment. A provider is not just a URL; it defines which models, streaming semantics, token accounting, and tool-call behavior are valid. A tool is not just a Python function; it has a schema, a transport, and side effects. Runtime design gets easier when these things have names and ownership rules. MCP is one example of this industry move toward explicit tool contracts across process boundaries.[6]
The fourth idea is provenance. If a session forks, which branch introduced the useful evidence? If two branches merge, which chunks were inherited and which were new? If a human reviewer accepts a result, what part of the runtime path is being trusted? These questions are not solved by a longer prompt. They require lineage in the object model.
| Systems idea | Agent-runtime version | OpenRath v1.1 surface |
|---|---|---|
| Event log | Record text, tool deltas, tool results, and checks as typed runtime events. | Session chunks and streaming loop callbacks. |
| Checkpoint | Persist enough state to inspect or resume a run outside the original process. | Local session persistence and sandbox identity store. |
| Adapter | Normalize provider and tool differences behind stable contracts. | Provider registry and MCP tool adapter. |
| Lifetime management | Reuse expensive execution environments without losing ownership semantics. | Sandbox lifecycle and refcount-style reuse. |
| Provenance graph | Represent branch, detach, merge, and inheritance as inspectable lineage. | Session merge and lineage export. |
A good session record should let a reader answer five questions.
The practical test for a session-first runtime is not whether the internal abstraction sounds elegant. The test is whether a developer can read one failed or successful run and quickly recover the causal structure of the work.
The first question is what the model saw. This includes system text, user text, compressed context, and any tool result that later became part of the model's input. Without this, the reviewer cannot tell whether the model had enough information to act correctly.
The second question is which provider executed the request. Two providers may both expose a chat API, but disagree on model names, tool-call streaming, response normalization, retries, token accounting, and error messages. A runtime that hides provider identity makes portability look better than it is. A runtime that records provider identity makes portability debuggable. This is also why SDK-level sessions are becoming first-class runtime concepts rather than optional debug output.[7]
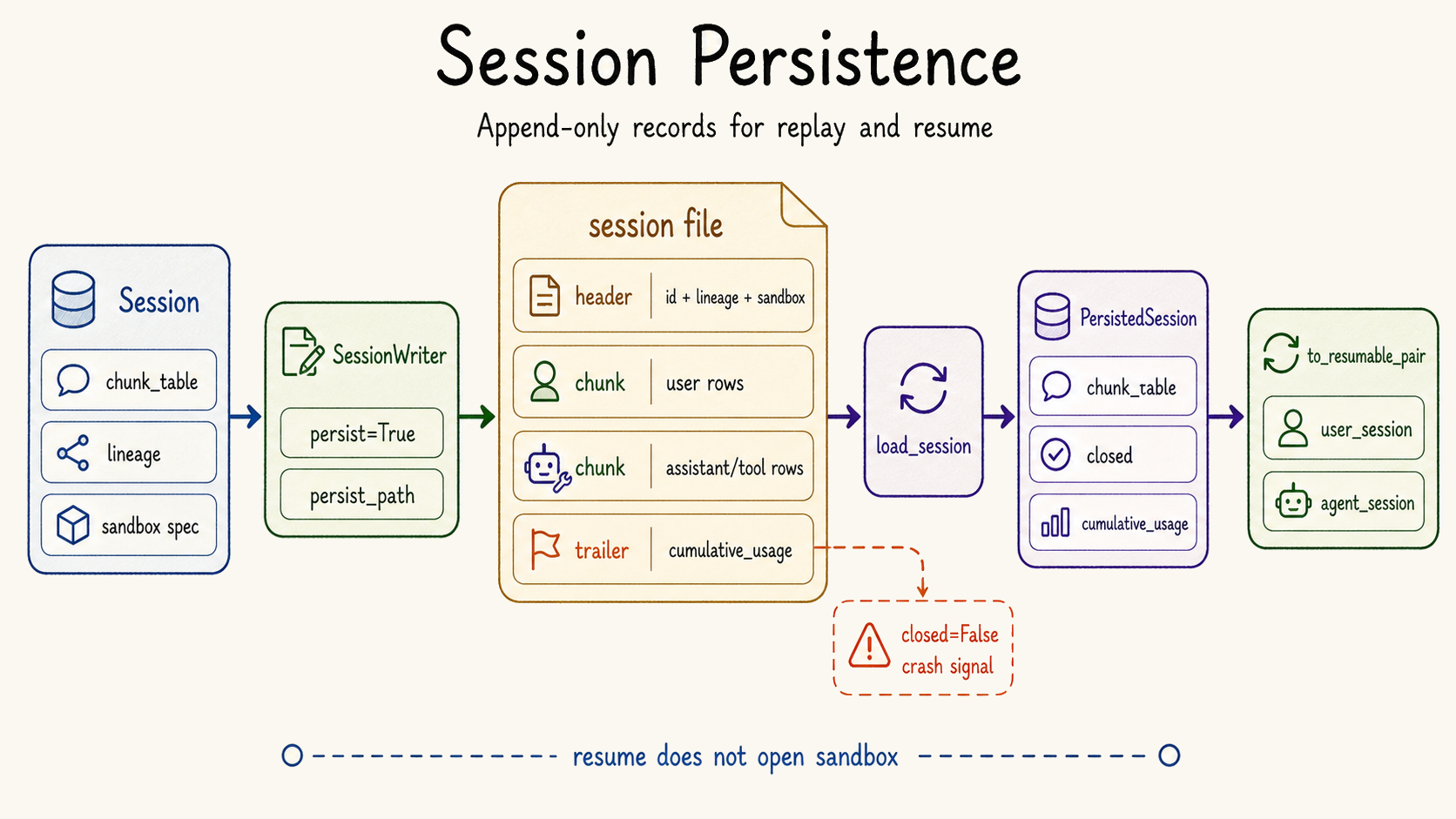
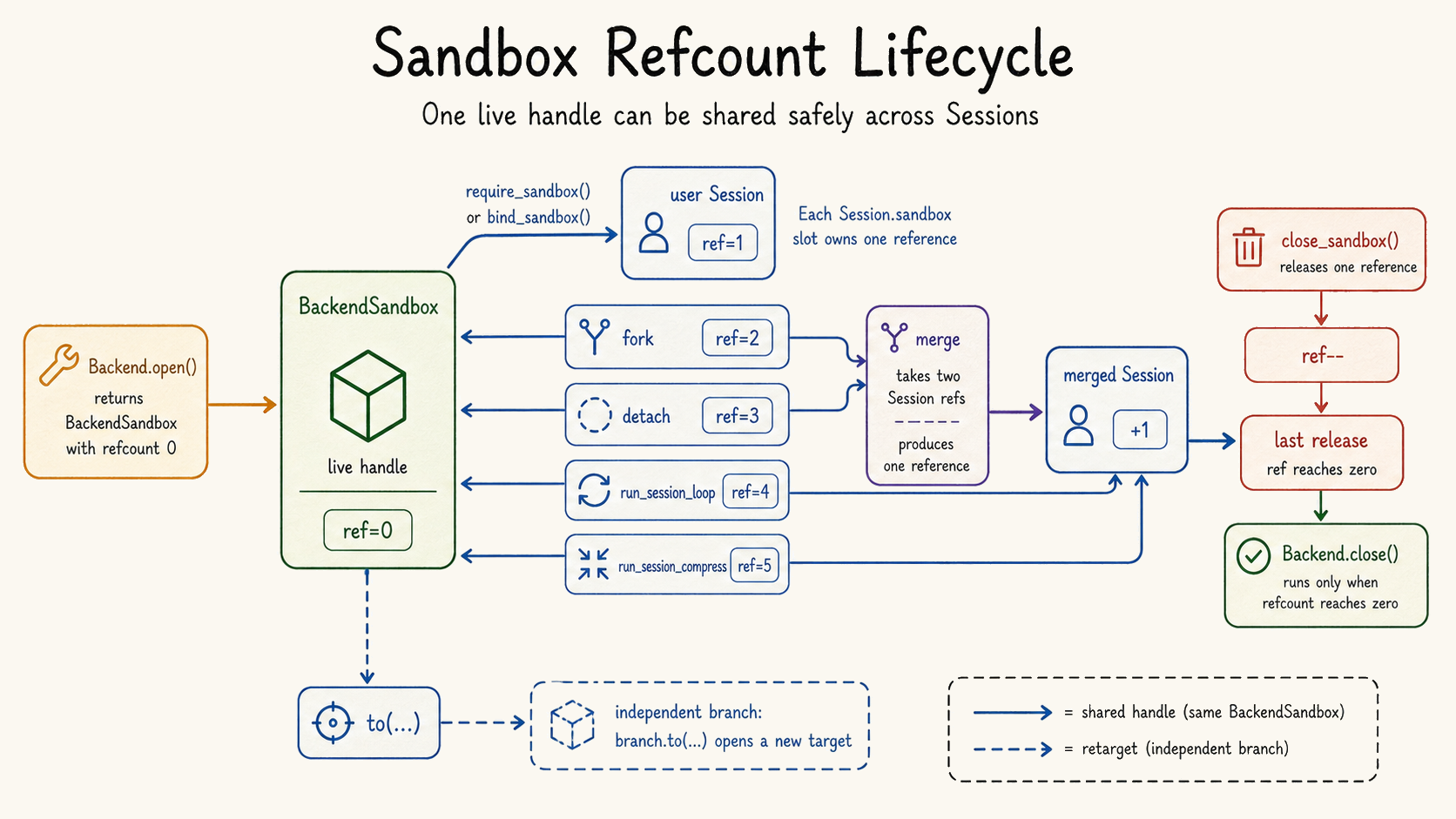
The third question is where the tools ran. A file-write tool is not just a function call. It has a working directory, a sandbox, a filesystem, and a lifetime. If the sandbox disappears, the evidence may disappear with it. If the sandbox is reused without ownership, one session may accidentally rely on state created by another. Persistent sandbox identity is the minimum structure needed to reason about these effects.
The fourth question is what changed. For a coding agent, this may be a patch. For a research agent, it may be a transformed dataset or a derived note. For a tool-using assistant, it may be an external side effect. A session should connect the change to the tool call that created it and the validation signal that made it acceptable.
The fifth question is where the final state came from. If a workflow forked, detached work, or merged branches, the final session should not pretend the path was linear. It should expose lineage. This is especially important for multi-agent workflows, where one agent may generate candidates, another may validate, and a third may merge the result into a final artifact.
| Question | Weak answer | Session-first answer |
|---|---|---|
| What did the model see? | A pasted prompt or final transcript. | Typed chunks that show user input, system context, tool results, and compressed history. |
| Which provider ran? | "An OpenAI-compatible endpoint." | A provider-specific client path with normalized request and response records. |
| Where did tools run? | "In a sandbox." | A persistent sandbox identity with explicit lifetime and reuse behavior. |
| What changed? | A final diff or output file. | Tool-call records, file effects, and validation signals attached to the same session. |
| Where did final state come from? | A prose summary of the winning attempt. | Fork, detach, merge, and lineage metadata. |
This checklist is deliberately plain. It is useful precisely because it does not depend on a new model capability. Better models will still call tools, touch files, stream partial results, hit provider-specific errors, and produce branches that need review. The runtime should make those facts cheaper to understand.
OpenRath's design move is to make the session the runtime boundary.
Many frameworks have sessions, traces, checkpoints, and tool logs. The OpenRath bet is narrower: make the session the object that developers pass around, persist, branch, merge, and inspect. That makes runtime evidence part of the user-facing programming model instead of a separate observability artifact discovered after something breaks.
Version 1.1 adds the missing pieces around that boundary. Provider dispatch becomes modular, local persistence gives sessions and sandboxes durable identity, sandbox lifecycle gets reuse semantics, MCP tools can enter the same tool table, session loops can stream execution events, and merge gives branch-and-join workflows explicit ancestry.
This design also keeps the abstraction small. OpenRath does not need every workflow to adopt a global orchestrator or a remote service first. A developer can begin with a local session, local tools, and a normal Python process. As the workflow becomes more serious, the same session can collect persistent records, sandbox identity, provider metadata, and lineage. The upgrade path is additive rather than a rewrite.
That additive shape matters for open-source adoption. A framework that demands a full platform before it can explain one run is hard to learn. A runtime that starts as a Python object and gradually earns more responsibilities is easier to inspect, test, and teach.
The v1.1 features are implementation pieces of the same idea.
The individual release items are easy to list. The more useful view is to ask what evidence each one adds to the session boundary.
This view also explains why the release includes both high-level features and lower-level maintenance work. Provider normalization is user visible. CI and linting are less glamorous. But a runtime boundary that claims to preserve evidence must be tested carefully, because small inconsistencies in chunks, tool results, or provider normalization quickly become debugging noise.
| Design claim | Current source surface | What the code actually provides |
|---|---|---|
| Provider dispatch is modular. | `src/rath/llm/registry.py`, `src/rath/llm/openai/`, `src/rath/llm/anthropic/` | Built-in OpenAI and Anthropic adapters self-register; third parties can register another chat client kind. |
| Session state can persist locally. | `src/rath/session/persistence/`, `src/rath/session/loop.py` | `run_session_loop(persist=True)` appends chunk rows to a per-session JSONL stream and writes a graceful trailer. |
| Sandbox identity is explicit. | `src/rath/backend/persistence/`, `src/rath/backend/abc.py`, `src/rath/session/session.py` | Local sandboxes can resolve to stable directories; sandbox handles use acquire/release reference counting. |
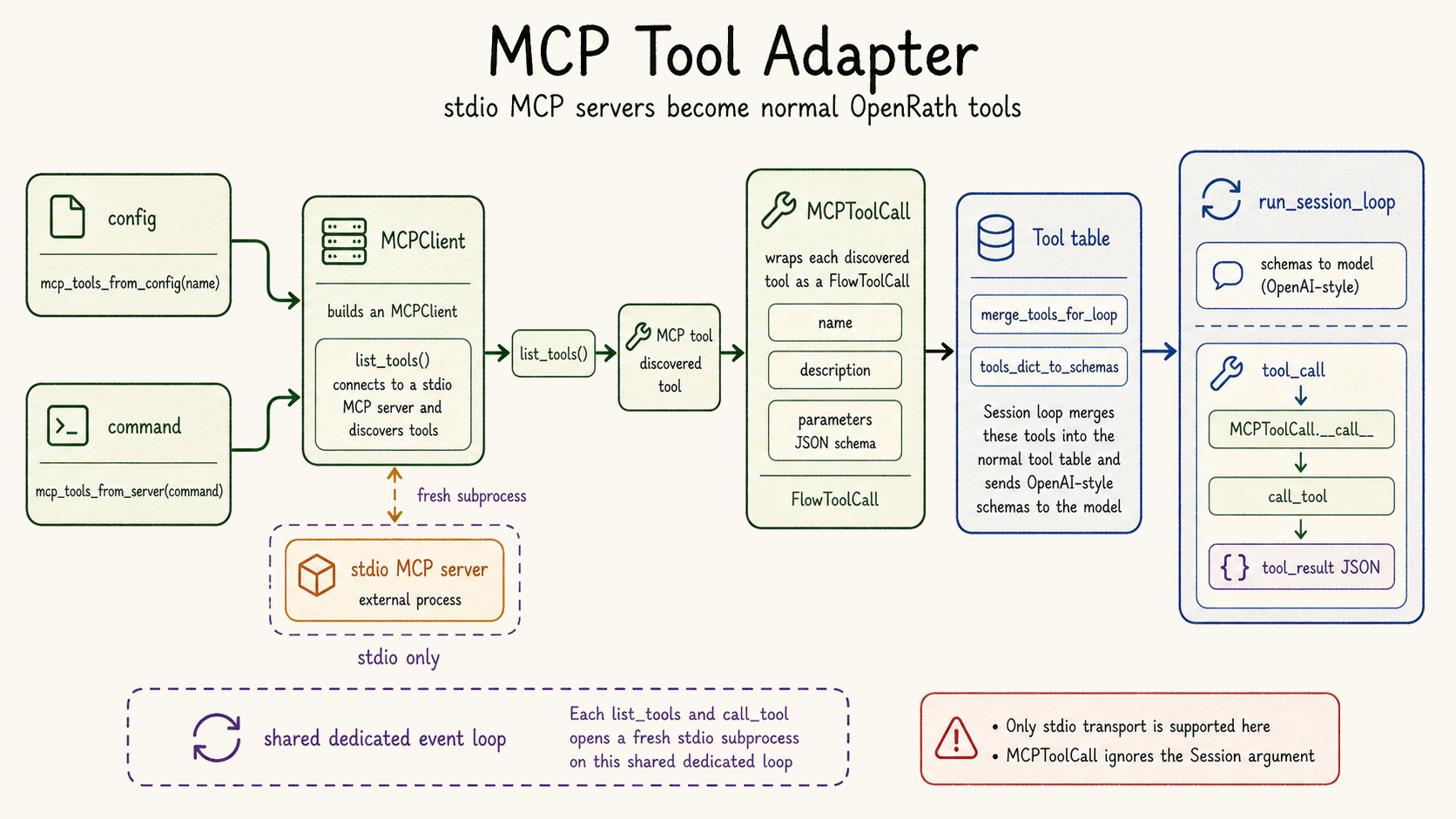
| MCP tools enter the same tool model. | `src/rath/flow/tool/mcp_adapter.py`, `src/rath/config/schema.py` | Stdio MCP servers are wrapped as `FlowToolCall` instances and can be discovered from OpenRath config. |
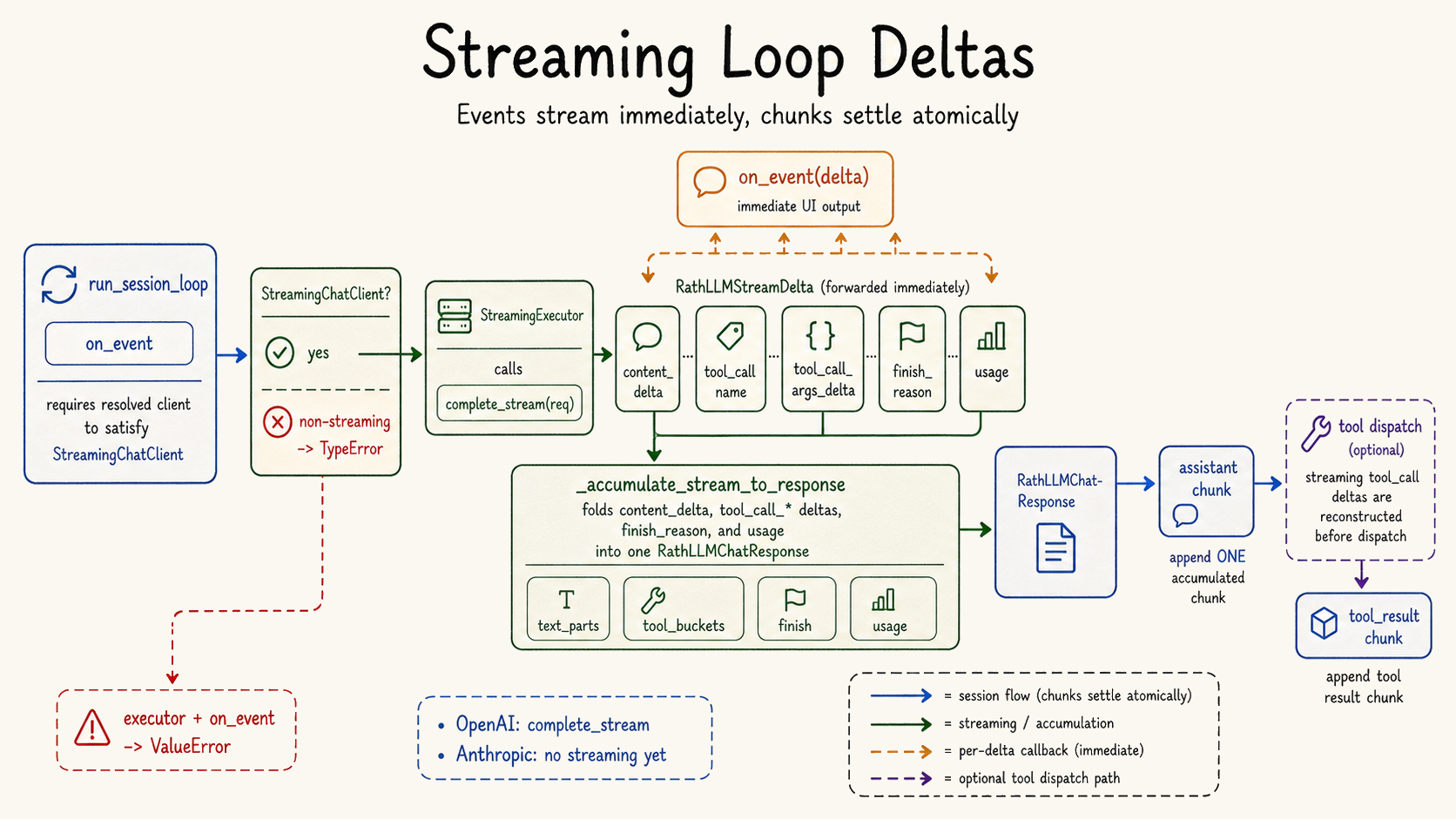
| Streaming is an event outlet, not a second loop. | `src/rath/session/loop.py`, `src/rath/llm/base.py`, `src/rath/llm/openai/client.py` | `run_session_loop(on_event=...)` forwards `RathLLMStreamDelta` events while accumulating the final assistant turn. |
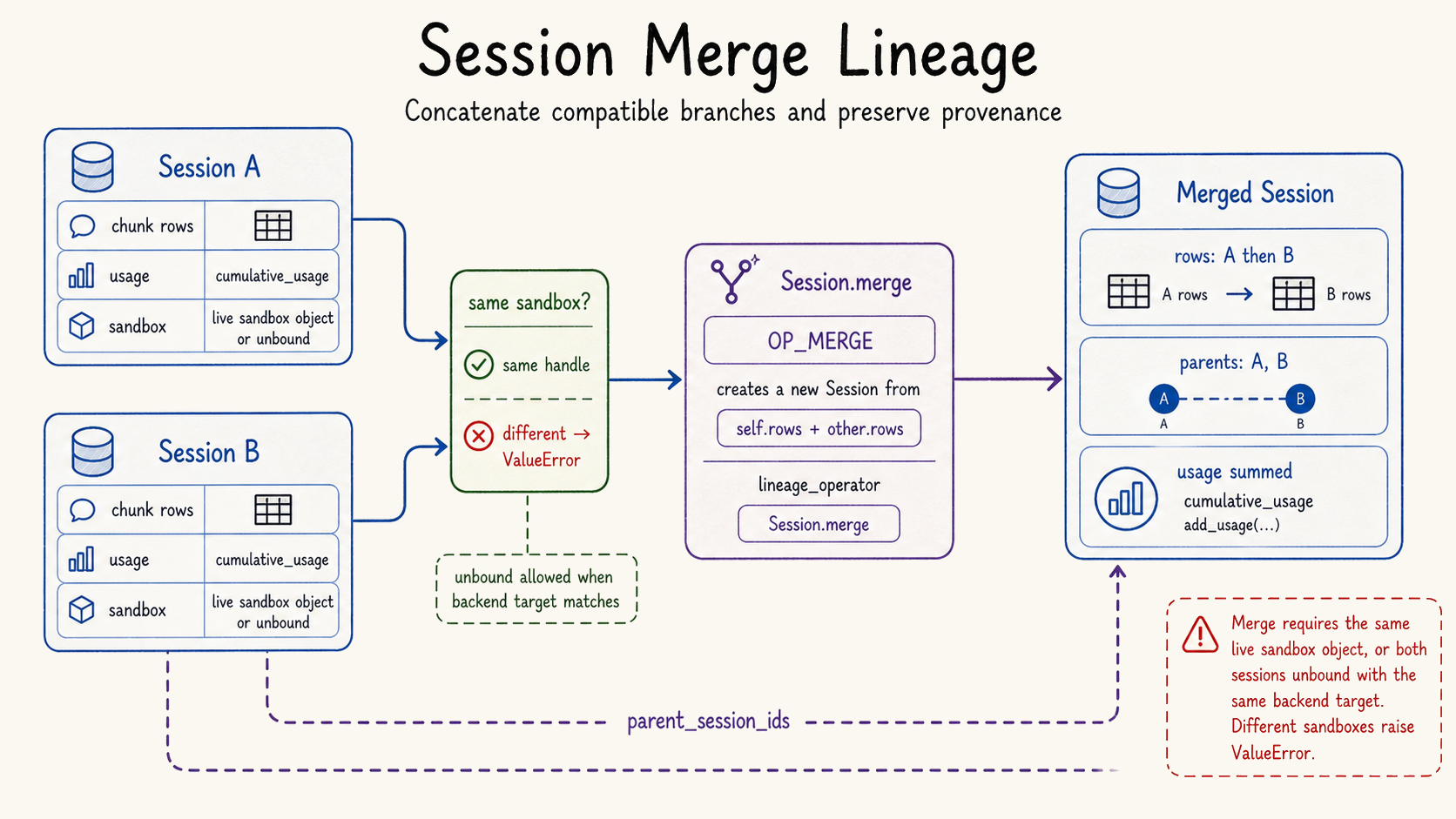
| Merge is lineage, not string concatenation. | `src/rath/session/session.py`, `src/rath/session/graph/export.py` | `Session.merge()` joins chunk tables, usage, shared sandbox identity, and parent session IDs. |
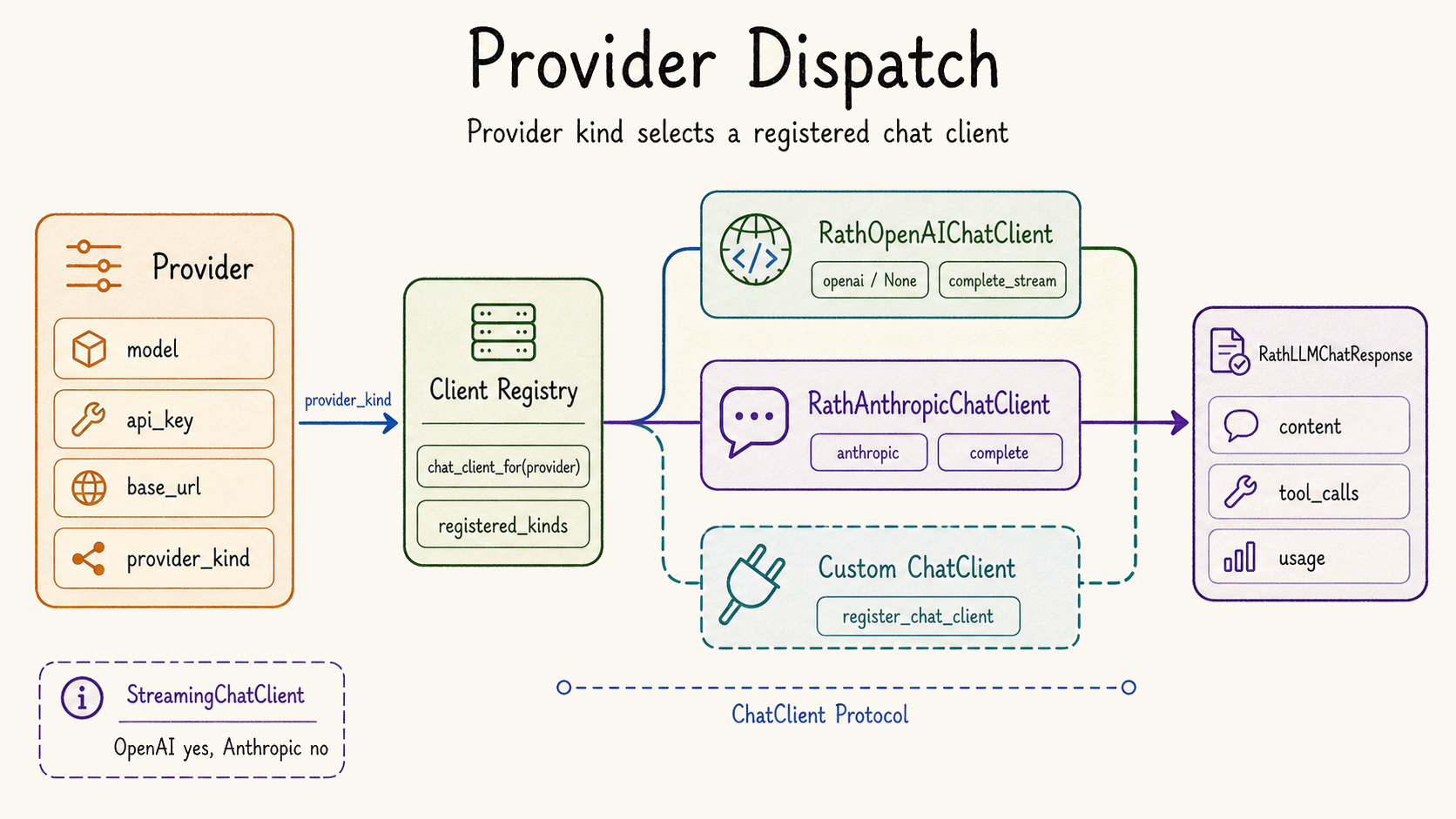
Provider registry
OpenAI-compatible and Anthropic paths can normalize request creation, stream chunks, tool call deltas, and usage without forcing workflow code to know every provider's shape.
Local persistence
Sessions and sandbox identities can survive process exits. That makes debugging and replay possible without depending on one terminal session staying alive.
Sandbox lifecycle
Refcounted reuse keeps expensive or stateful environments alive when they are still owned by active sessions, while still making close behavior explicit.
MCP adapter
External tool servers can be brought into the same tool-call and tool-result model used by local sandbox tools.
Sandbox identity
MCP tools
Merge and streaming make the execution path visible while it is still alive.
Long-running agent workflows fork. They try variants, detach subtasks, branch into tools, and later need to reconcile state. OpenRath v1.1 adds a session merge operation so those transitions can be represented as runtime state instead of informal notes.
Streaming complements merge. Merge answers "where did this state come from?" Streaming answers "what is happening right now?" Together they push OpenRath toward a runtime where users can observe the live execution path and then inspect the persistent lineage after the run ends.
Lineage after the run
Events during the run
The payoff is not just cleaner internals. It is a different class of applications.
Once a session is a durable runtime object, several workflows become easier to build. They are hard to support if a run is only a transcript plus a few disconnected logs.
The most immediate application is not a flashy autonomous agent. It is a quieter engineering loop: run an agent, preserve the path, let a human inspect the evidence, and only then accept the result. That loop is how agent systems can become useful inside real repositories, notebooks, research pipelines, and production operations.
Debuggable coding agents
A maintainer can inspect the exact provider response, tool call, file edit, lint failure, and final validation that produced a patch. That is more useful than a confident final summary, and it matches the direction of real-repository coding-agent evaluation.[5]
Resumable research workflows
A literature review, data transform, or benchmark run can pause, branch, and resume without losing which sandbox or intermediate evidence belonged to which attempt.
Agent evaluation beyond pass rate
Evaluators can compare not only whether an agent reached the answer, but how many tool calls, retries, branches, and validation steps were needed.
Human review with provenance
A reviewer can ask where a claim, file edit, or tool result came from. The runtime can answer with lineage instead of relying on the agent to explain itself after the fact.
The release also tightens the path from local work to public code.
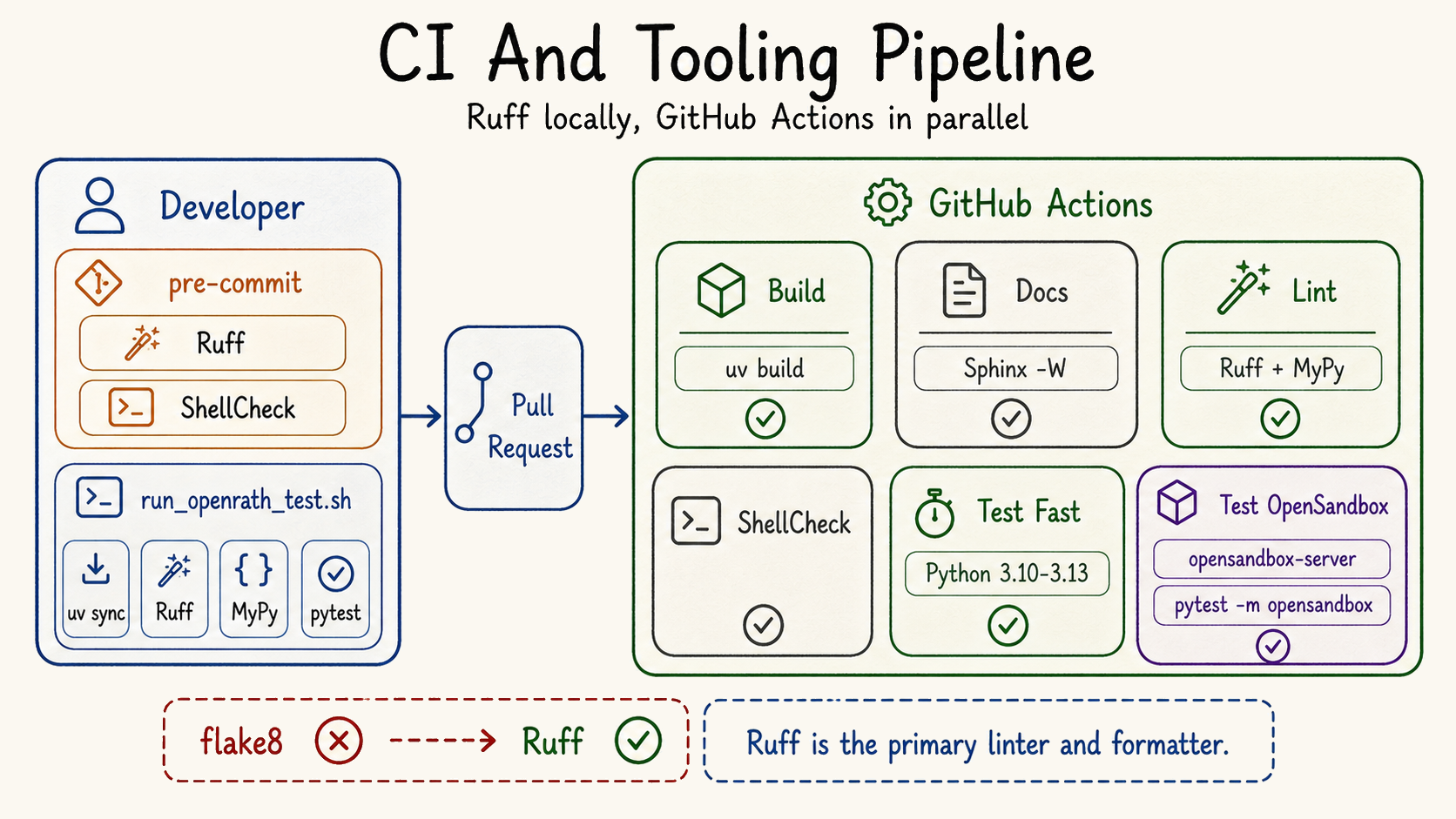
Durable runtime features need repeatable maintenance. This release moves linting from flake8 toward Ruff and adds GitHub CI/CD coverage for OpenRath. The documentation also now tracks the source more directly: configuration, LLM providers, MCP usage, streaming, persistence, and lineage all have public docs coverage.
| Area | v1.1 contribution | Runtime impact |
|---|---|---|
| CI/CD | GitHub workflows for repeatable checks. | Public changes are easier to validate before release. |
| Ruff | Faster, stricter linting path replacing the older flake8 setup. | Contributor feedback is faster and more consistent. |
| Docs | English public docs now cover the new v1.1 runtime layers. | Users can learn the source-facing APIs without reading every module first. |
What this release does not solve yet, and why that is useful.
OpenRath v1.1 does not finish the runtime story. It establishes the object boundaries needed to make the next work more concrete: richer persistence backends, stronger replay, tool provenance, session graph visualization, and production-grade sandbox deployment.
The honest limitation is that durable sessions are a foundation, not a complete observability system. OpenRath still needs better visual lineage explorers, stronger replay semantics, more persistence backends, and clearer production deployment stories for OpenSandbox and MCP servers. The value of v1.1 is that these are now extensions of a coherent runtime object instead of separate feature requests.
Near-term product work
Add more persistence tutorials, tighten configuration helpers, document OpenSandbox deployment, and make MCP transports easier to configure in real projects.
Near-term research work
Export more lineage graphs, compare final-only logs with session traces, and study whether durable session evidence reduces debugging cost in real agent failures.
- Public docs docs.openrath.com
- Source repository github.com/Rath-Team/OpenRath
- Suggested reading order Installation, tutorials, developer notes, then API reference.
- Design summary Session-first means that runtime evidence is attached to a durable object, not left behind as incidental logs.
References and related work.
The argument above is grounded in two bodies of work: language models acting through tools, and software systems that preserve execution state through traces, checkpoints, and durable records.
-
Tool-use agents
ReAct: Synergizing Reasoning and Acting in Language Models
Introduces an early and influential framing for interleaving model reasoning with actions.
-
Tool learning
Toolformer: Language Models Can Teach Themselves to Use Tools
Shows tool use as a learnable language-model behavior rather than only an application wrapper.
-
Agent tracing
OpenAI Agents SDK: Tracing
Shows tracing as a first-class operational surface for agent runs.
-
Durable execution
LangGraph: Durable Execution
Documents checkpoint-backed recovery and resume semantics for long-running graph workflows.
-
Workflow durability
Temporal: Workflow Execution
Explains durable workflow execution and event history as a basis for reliable long-running work.
-
Workflow checkpoints
LlamaIndex Workflows
Documents event-driven workflows and checkpoint/resume patterns in an agent-oriented library.
-
Agent state
AutoGen AgentChat: Managing State
Shows how agent and team state can be saved and loaded in multi-agent applications.
-
Traces and spans
OpenTelemetry: Traces
Defines traces and spans as a way to represent causal paths through distributed systems.
-
Real-repo evaluation
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Frames software-engineering agents around real repository issues rather than isolated snippets.
-
Tool protocol
Model Context Protocol: Tools
Specifies a shared way for servers to expose tools that models can call.
-
Agent sessions
OpenAI Agents SDK: Sessions
Documents session memory as an SDK-level concept for maintaining conversation history.
-
OpenRath docs
OpenRath Documentation
Public documentation for the v1.1 session, backend, provider, MCP, streaming, and lineage surfaces.